

This plugin provides an opinionated way of using Flyway, for your SQL database migrations.
Database migration (also known as database evolution) is the process of upgrading the schema of a database in a predictable and replayable way.
The migration approach this plugin provides:
.sql" text files).
You use standard Java classes to define the migrations to be executed. By doing do, you use Java code and you have access to any libraries you need.
The migrations classes targetting a specific DataSource must
all be located under the same package, and their names must follow some rules. Here's an
example of some migration classes for a "mainDb" DataSource:
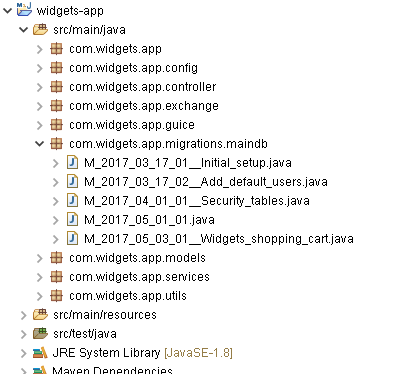
As you can see in this example, all the migrations classes for the main database are
located in the same package ("com.widgets.app.migrations.maindb").
A migration class extends SpincastFlywayMigrationBase.
You simply have to implement the runMigration(...) method in order to specify the queries to run:
public class M_2017_04_01_01__Security_tables extends SpincastFlywayMigrationBase {
@Inject
public M_2017_04_01_01__Security_tables(@MainDataSource DataSource dataSource,
JdbcUtils jdbcUtils) {
super(dataSource, jdbcUtils);
}
@Override
protected void runMigration(Connection connection) {
createPermissionsTables(connection);
createRolesTables(connection);
//...
}
//...
}
Explanation :
SpincastFlywayMigrationBase and follows the
naming convention.
DataSource to
target.
runMigration(...)
method. This method receives the connection to use to run your SQL queries. In this method, you
can directly write and execute some SQL queries or you can call some existing repositories to do it.
The name of a migration class must follow some rules:
M_" ("M" is for "migration").
M_" represents the version
of the migration. Here you can use different formats, but you must stay
consistent! We suggest two kinds of formats:
2017_04_01_01". Here, the date
is "2017-04-01" and it would be the first migration of the day. Another
migration executed on the same day would be named "2017_04_01_02".
12_0_3"
or "2_1_37_1".
This would follow the standard Semantic Versioning.
M_2017_04_01_01__Security_tables". The
"__" and everything coming after it will be ignored. This allows you to add
a description and make the name more meaningful.
![]() The migrations classes are executed in order, based on the versions extracted
from their names... Make sure you keep a consistent naming convention!
The migrations classes are executed in order, based on the versions extracted
from their names... Make sure you keep a consistent naming convention!
By extending SpincastFlywayMigrationBase, the connection provided by Flyway to run the migration is going to be used to run all SQL requests, both directly and indirectly, as long as you use the scopes provided by the Spincast JDBC plugin.
For example, let's say one of the steps in your migration is to
add a new column to your users table. You may already
have a UserService providing a
updateUsers(...) method... It would be nice to be able to reuse
the logic provided by that service to update your existing users with a custom
value, once the new column is added! But Since the updateUsers(...) method
doesn't accept any Connection parameter, and may itself call a
UserRepository component, how could the SQL request being performed in the end
use the proper connection provided by Flyway?
The answer is that a specificConnection scope has been created in the base class, and your migration code (direct and indirect) is all ran inside of it!
The second step to set up your migrations is to create a migration context, the
component by which a migration is actually started. In this context, you specify the DataSource to be migrated and where to find the
migration classes to execute.
To create such context, you inject the
SpincastFlywayFactory
component and you call the createMigrationContext() method. Using the created context, you then execute the migration:
@Inject
SpincastFlywayFactory factory;
SpincastFlywayMigrationContext migrationContext =
factory().createMigrationContext(myMainDataSource,
"public",
M_2018_01_01_01.class.getPackage().getName());
migrationContext.migrate();
Explanation :
DataSource to
be migrated.
![]() Your migrations should probably be executed as soon as your
application starts (using an init method, for example).
The plugin will detect any migration classes which haven't been applied yet and will
use them.
Your migrations should probably be executed as soon as your
application starts (using an init method, for example).
The plugin will detect any migration classes which haven't been applied yet and will
use them.
The Spincast Flyway Utils plugin depends on the Spincast JDBC plugin, a plugin which is not
provided by default by the spincast-default artifact. This dependency plugin will be automatically installed,
you don't need to install it by yourself in your application (but you can).
Just don't be surprised if you see transitive dependencies being added to your application!
1. Add this Maven artifact to your project:
<dependency>
<groupId>org.spincast</groupId>
<artifactId>spincast-plugins-flyway-utils</artifactId>
<version>2.2.0</version>
</dependency>
2. Add an instance of the SpincastFlywayUtilsPlugin plugin to your Spincast Bootstrapper:
Spincast.configure()
.plugin(new SpincastFlywayUtilsPlugin())
// ...
 What's new?
What's new?